
Exploring Randomness in Mobile Gaming
I know we all expect mobile games to be rigged. Anything goes in the name of engagement and retention numbers, but it’s always hard to prove. Hidden odds, complicated algorithms and “power ups”, and incomprehensible stat sheets all obfuscate the actual pRNG (psuedo Random Number Generator). But recently, a mobile game I’d been playing held a special event that let you roll dice. This should be a clear look straight at the results of the RNG, but is it?
To find out, I rolled a pair of electronic dice 200 times, meticulously noting the values in a spreadsheet. The things we do for science. At first glance, intuitively, the data looks off:
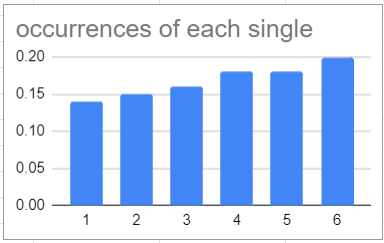
That doesn’t look right at all. These should be even (aside from random noise), and instead we have a evenly sloped line – showing that higher numbers are encouraged on the dice (and in-game, higher values are rewarded). Now that we’ve got that down, lets look at doubles (also rewarded in-game):
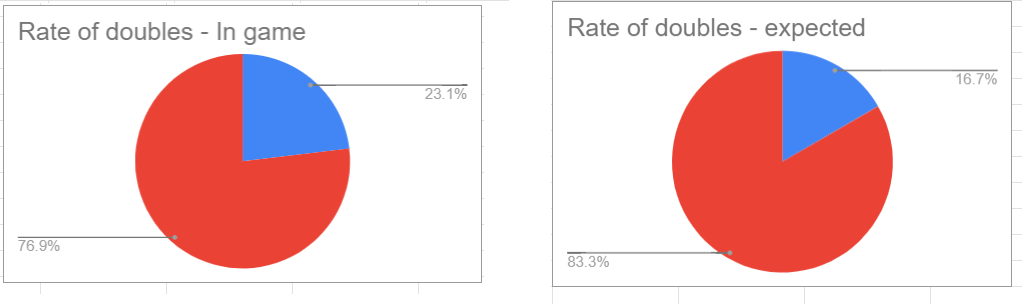
We’d expect a 16% chance (first dice comes up X. Second dice has a 1:6 chance of matching X), but we’re at 23%. More damningly, Doubles occurred at a 30% rate in the first third of the data (not pictured, see spreadsheet at end). It seems the odds change as you play, starting strong to hook you before tapering towards (but never getting to) a natural rate.
The final aspect that I chose to examine was the rate of 7s. 7s are also rewarded, but rewarded so heavily it would make the game too easy if they came up too often.
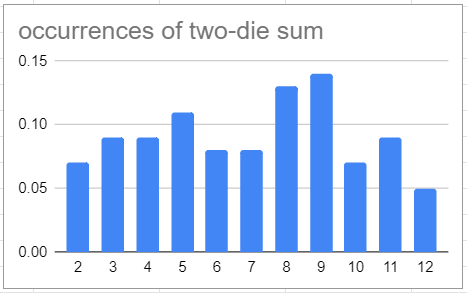
But seven should be the most commonly rolled sum. If we put together a table we can calculate the exact chances:
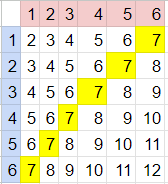
There are 6 out of 36 possible results that are 7, more than any other number. However in our gameplay 7 came up less often than 3, which only has 2 possible creations! (1+2 or 2+1).
So here we have several indicators that the RNG is not truly random, nor even psuedorandom, but instead a weighted number generator that is watching the combined totals in order to manipulate the player into playing more, striving to get that 7 that should be just around the corner. But do we have proof? Perhaps I just got particularly unlucky several hundred times in a row. So how unlikely is it for this to occur?
For the two-dice example, we only had 6^2 options, so we could build a table and calculate the odds by hand. However, in order to build a table to match all 200 runs, we’d have (6^2)^200 options! Even google gives up at that point.
This is where we get to the hard math. Binomial distributions – essentially, how likely is a combined result of X, given N trials and a probability per-trial of p. This requires a lot of summations, factorials, and integrations… I don’t have time for that, I have fake dice to roll! Luckily excel will do it for us: BINOM.DIST([occurrences], [trials],[probability per trial], [cumulative or single])
So, for example, the odds of flipping 5 or more heads in 10 tosses is BINOM.DIST(5,10,.5, TRUE [meaning x or more, not exactly X]), and excel tells us this is likely 62% of the time. So lets look at our two biggest red-flags:
The chance that we got only 16 (or less) sevens, given 6/36 odds (6 of the 36 possible combinations result in 7), out of 200 rolls:
BINOM.DIST(16,200,6/36,TRUE) = .03%, about 1:3000 odds.
The chance that we got 46 (or more) pairs, in 199 trials, given 1:6 odds:
BINOM.DIST(46,199,1/6,TRUE) = .7%, about 1:120 odds.
And we can combine these and look for the chances that these both occur together, 1:(3000*120) = 1:360k. I didn’t adjust for the lack of 7s making doubles more likely, but these rough numbers are close enough to prove the point. I’m sure if we added the chances for the single dice rolls as well we’d be in 1:1M odds that these results are natural.
Potential mechanism of action: There may be a simple algorithm that would result in all of these red flags: If a 7 is rolled, flip a coin. If heads, return 7. If tails, increment one dice. This rule change would explain the slope of the singles, the lack of 7s, and the increase in doubles – but this increase would be located only on 4:4. So to test this hypothesis, lets create a graph showing the frequency of each pair:
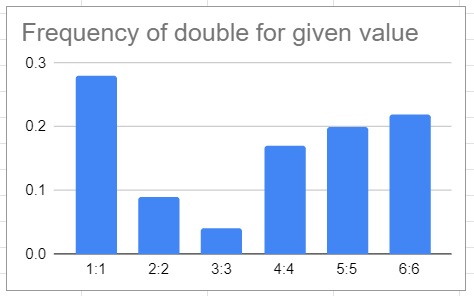
We’d expect a flat chart, so this is ridiculously unnatural. However, it’s not unnatural in the way we hypothesized above, so the proposed algorithm is clearly not the one they are using. Fewer ones were rolled than any other number, and yet they are most likely to be in a pair. Clearly something else is going on.
So remember: When you’re not paying for the product, you may be the product.
*Update!*
More data more better, right? I gathered another 280 pairs and reran the analysis.
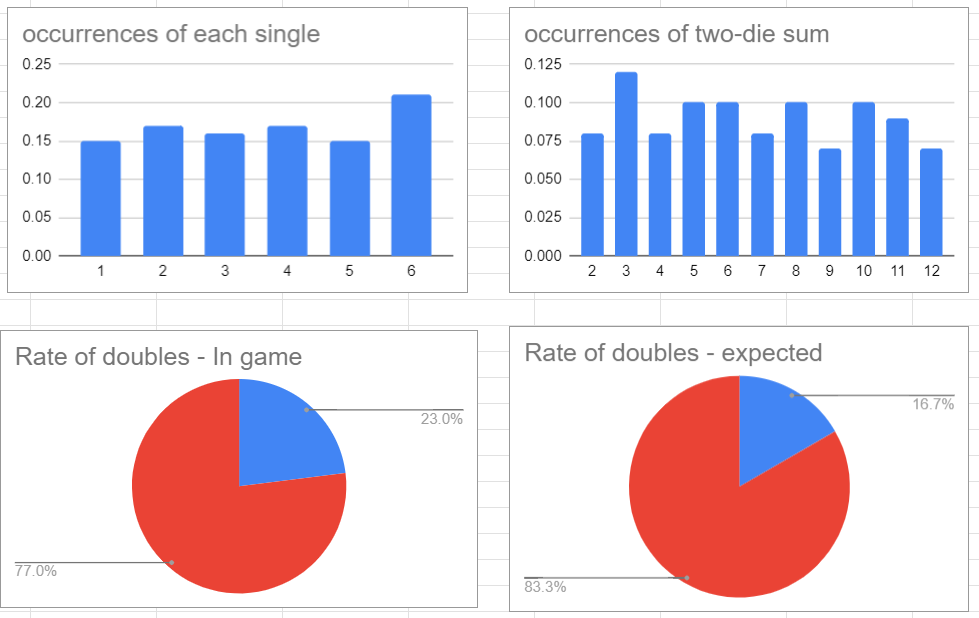
The rate of doubles is identical at 23%. The individual numbers were a bit more mixed, but still trended towards the most 6s, and not nearly the correct number of sevens.
Rerunning the binomial distribution on the combined data set leads to:
23% rate of doubles in 475 throws: .017% = 1:6000
(39)7s in 475: 1:17M
Both: 1:100T
So yeah.
Postscript: All the raw numbers and calculations are available here: https://docs.google.com/spreadsheets/d/1h1KqF-IuFLbCTrlajyu_8774xoV1nsafQXCPMrw_5mU/edit?usp=sharing . If you’d like to do further analysis or correct any mistakes I may have made, please reach out, we’d love to get even deeper into these numbers.

You must log in to post a comment.